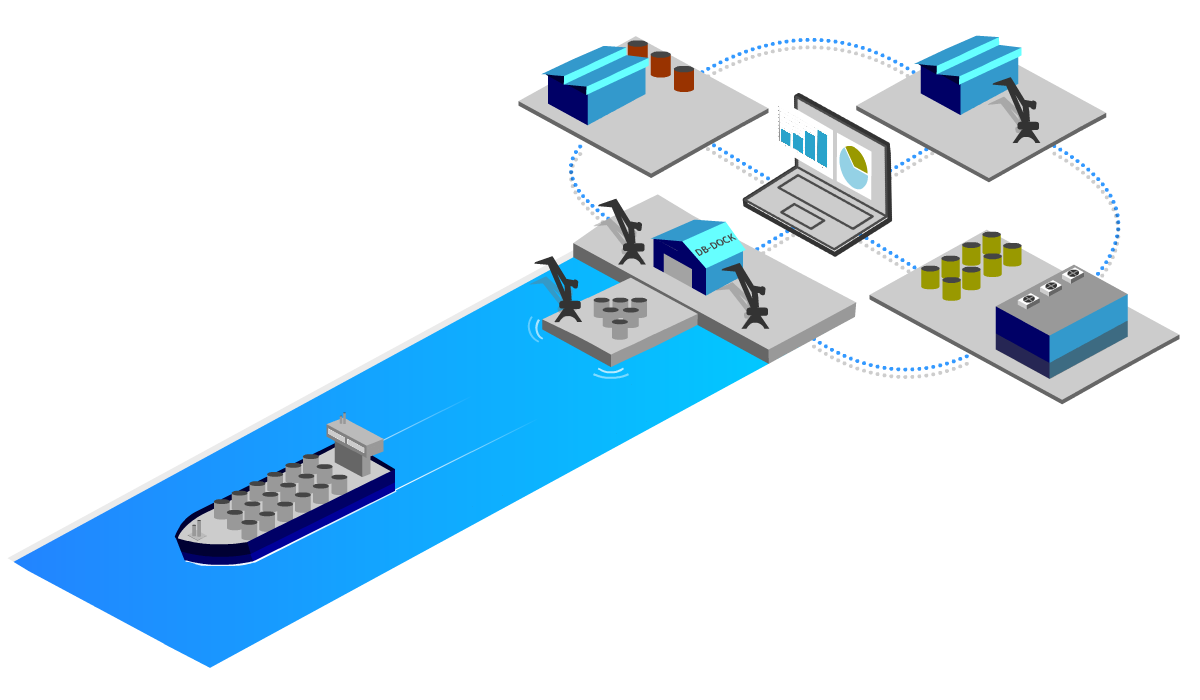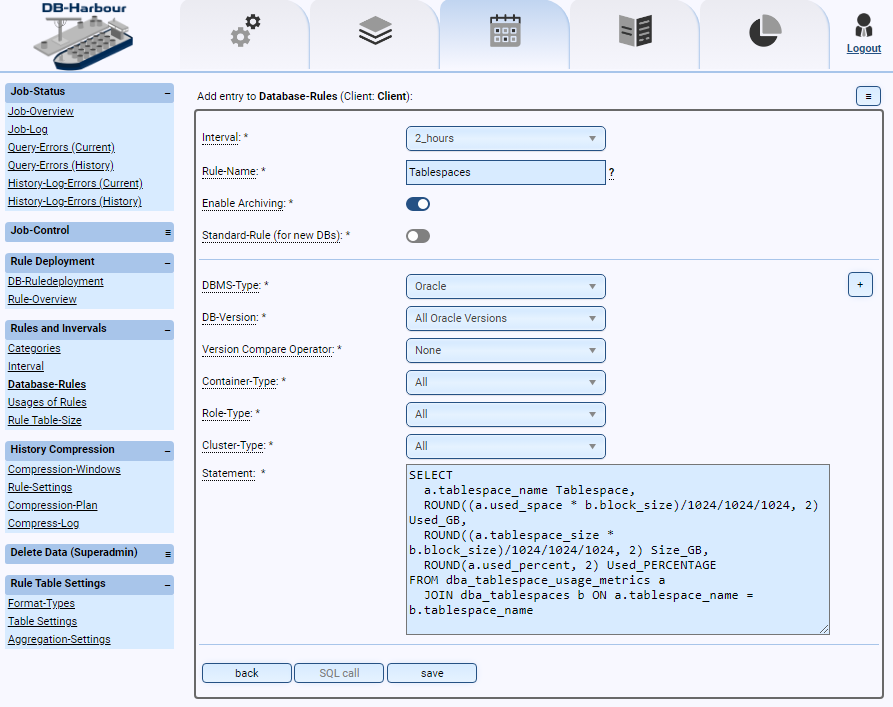
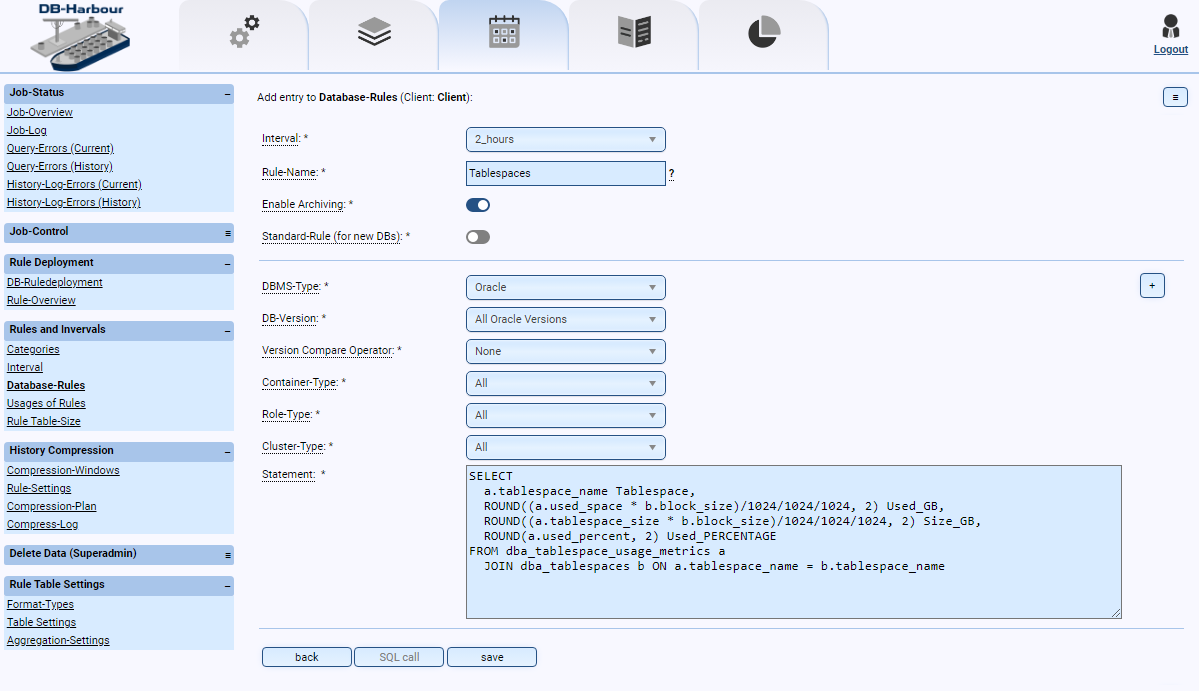
Einsatzmöglichkeiten
-
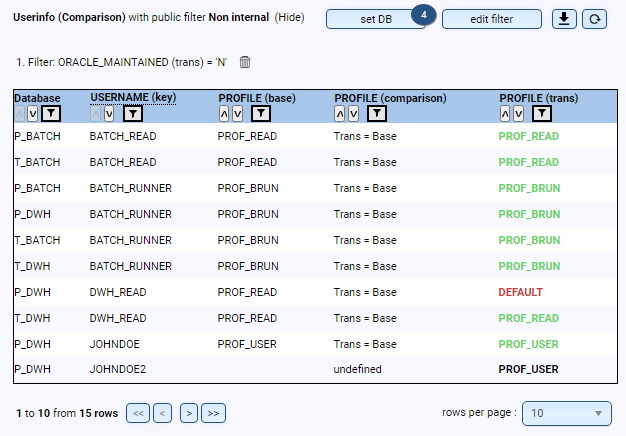
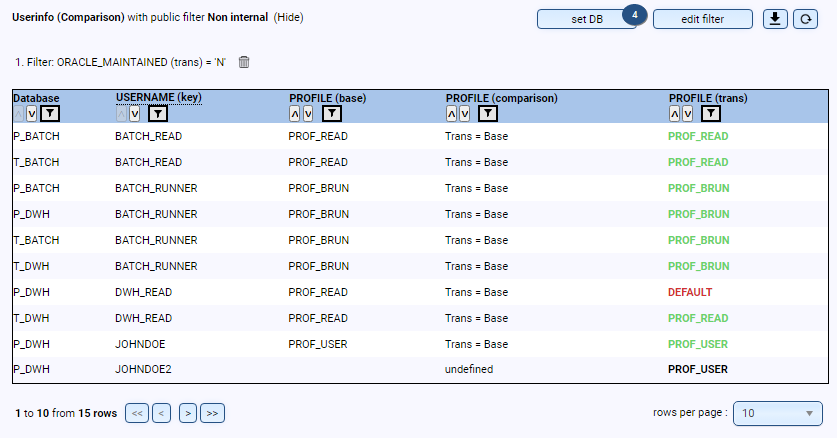
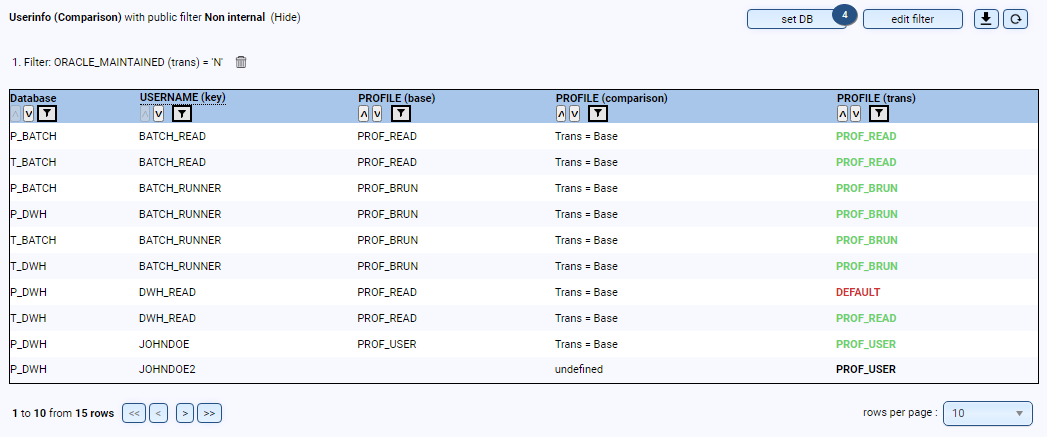
Ob für interne Prüfungen oder externe Audits (z.B. CIS-Auditierung) - mit DB-Harbour können Sie prüfen, ob Ihre Datenbanken den Sicherheitsvorgaben entsprechend konfiguriert sind, und erhalten automatisch einen dauerhaften Überblick sowie eine Historisierung:
- Liegen die Datenbank-User in den korrekten Profilen und welche Passwort-Versionen besitzen die User?
- Existieren User, die sich noch nie angemeldet haben oder die gelöscht werden müssen?
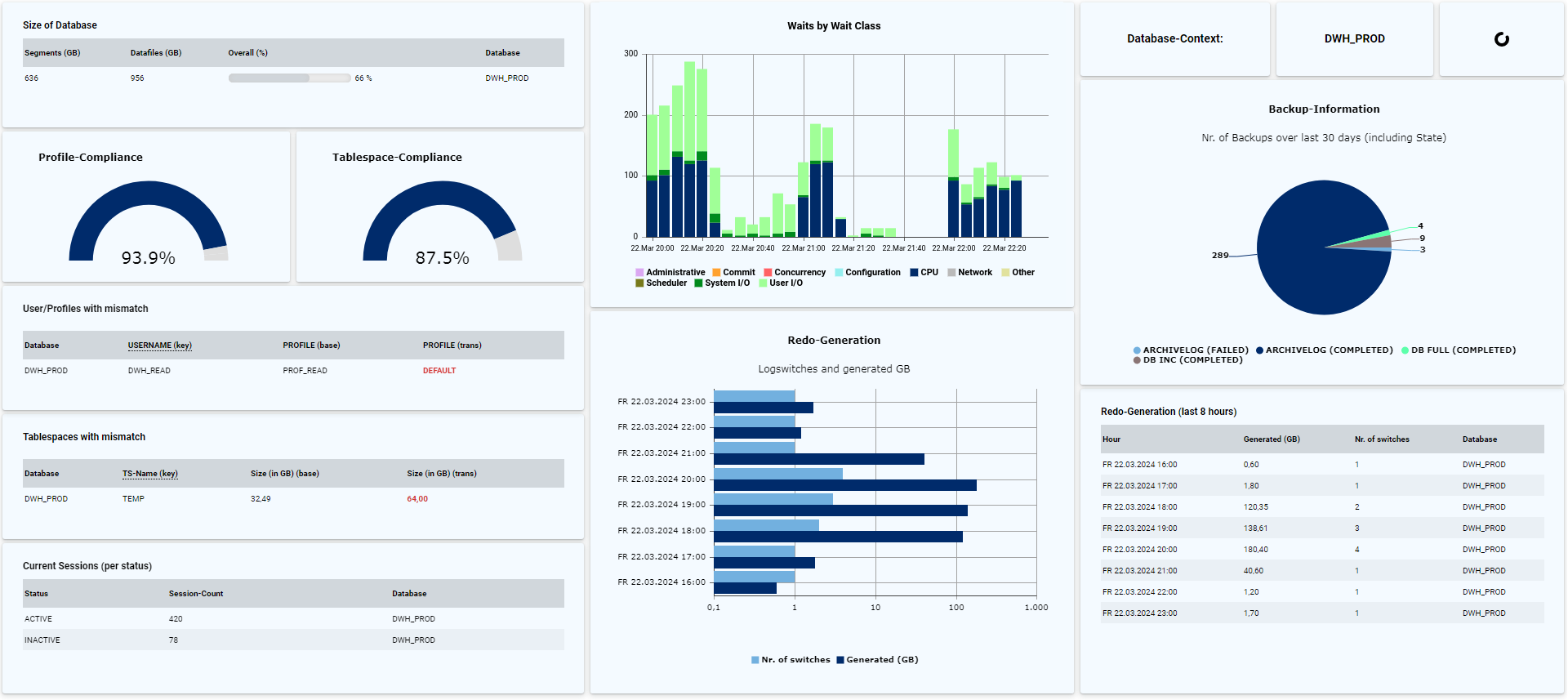
- Einlesen, zentrale Speicherung und Auswertung der Auditierungs-Views (z.B. Fine Grained Auditing oder Unified Auditing)
- Vorbereitung von Audits und dauerhafte Sicherstellung der Security-Anforderungen (z.B. Prüfung auf Public Database-Links oder ANY-Grants)
- Weitere Prüfung eigener Sicherheits-Standards (z.B. Konfiguration von Database-Vault oder TTS-Encryption)Ob für interne Prüfungen oder externe Audits (z.B. CIS-Auditierung) - mit DB-Harbour können Sie prüfen, ob Ihre Datenbanken den Sicherheitsvorgaben entsprechend konfiguriert sind, und erhalten automatisch einen dauerhaften Überblick sowie eine Historisierung:
- Liegen die Datenbank-User in den korrekten Profilen und welche Passwort-Versionen besitzen die User?
- Existieren User, die sich noch nie angemeldet haben oder die gelöscht werden müssen?
- Einlesen, zentrale Speicherung und Auswertung der Auditierungs-Views (z.B. Fine Grained Auditing oder Unified Auditing)
- Vorbereitung von Audits und dauerhafte Sicherstellung der Security-Anforderungen (z.B. Prüfung auf Public Database-Links oder ANY-Grants)
- Weitere Prüfung eigener Sicherheits-Standards (z.B. Konfiguration von Database-Vault oder TTS-Encryption) -
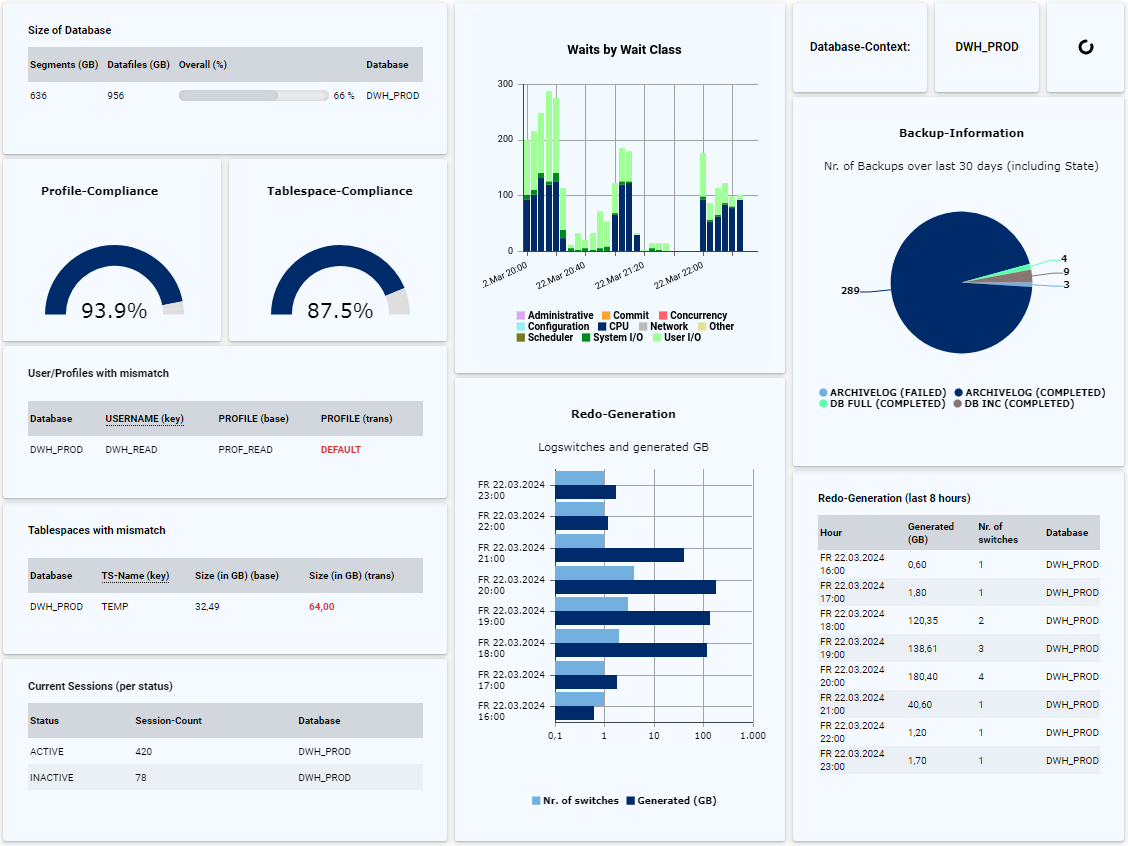
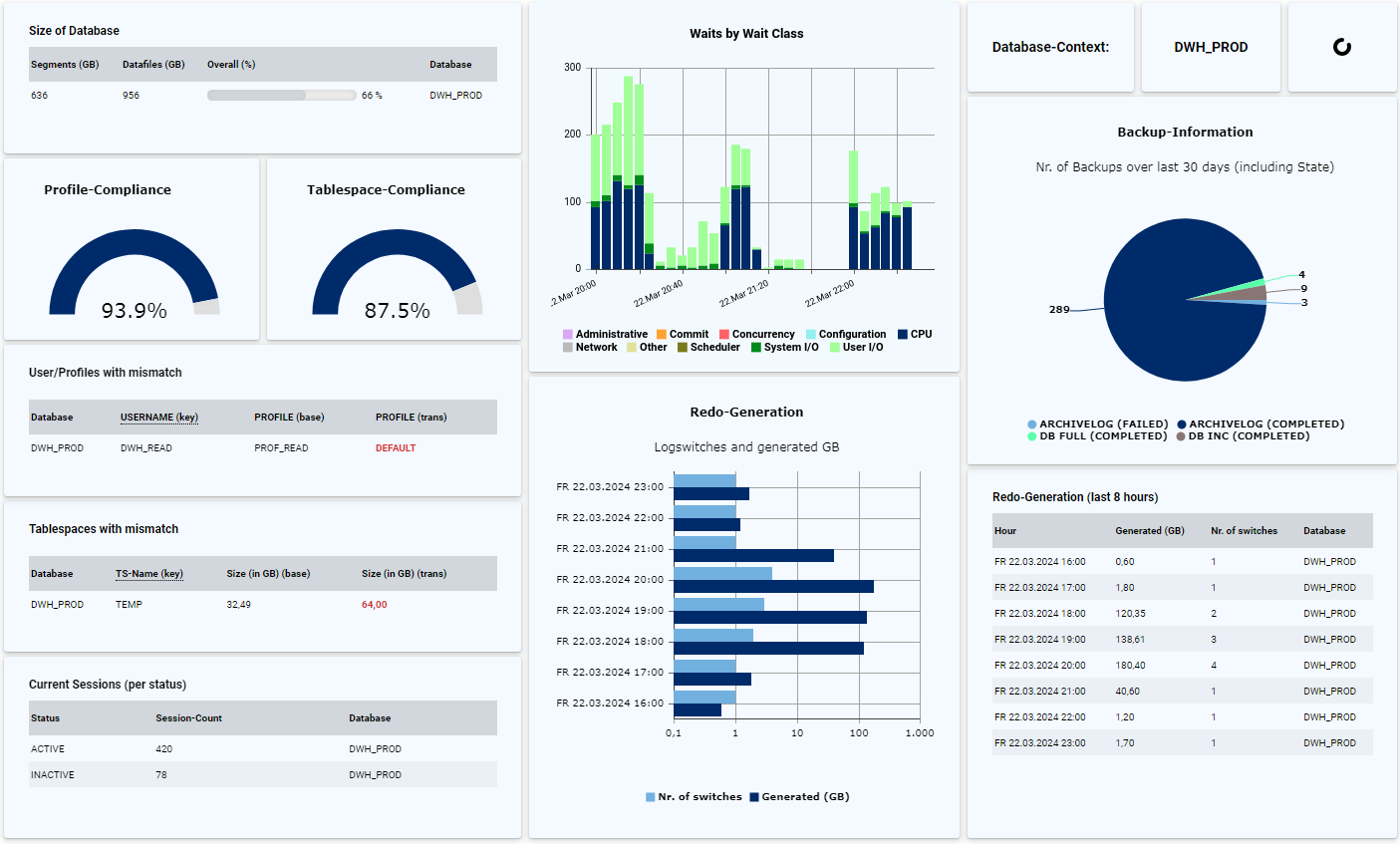
Im Gegensatz zu Monitoring-Tools kann mit DB-Harbor eine tiefergehende Backup-Analyse durchgeführt werden, mit der sich zukünftige Probleme bereits im Vorfeld umgehen lassen. Mit Hilfe von DB-Harbour können viele Fragen rund um den Themenbereich Backup von Oracle-Datenbanken schnell, komfortabel und dauerhaft geklärt werden:
- Gibt es neue Datafiles oder PDB's die noch nie gesichert wurden?
- Wie ist der Status und Timestamp von Datafile-Copies?
- Freier Platz innerhalb der Flash Recovery Area und in ASM-Diskgroups
- Sind Sicherungen auf Fehler gelaufen?
- Wie haben sich das Backup-Volumen und die Backup-Laufzeiten über die letzten Jahre entwickelt?
- Ist eine Änderung der Backup-Strategie sinnvoll und kann ggf. Platz eingespart werden?Im Gegensatz zu Monitoring-Tools kann mit DB-Harbor eine tiefergehende Backup-Analyse durchgeführt werden, mit der sich zukünftige Probleme bereits im Vorfeld umgehen lassen. Mit Hilfe von DB-Harbour können viele Fragen rund um den Themenbereich Backup von Oracle-Datenbanken schnell, komfortabel und dauerhaft geklärt werden:
- Gibt es neue Datafiles oder PDB's die noch nie gesichert wurden?
- Wie ist der Status und Timestamp von Datafile-Copies?
- Freier Platz innerhalb der Flash Recovery Area und in ASM-Diskgroups
- Sind Sicherungen auf Fehler gelaufen?
- Wie haben sich das Backup-Volumen und die Backup-Laufzeiten über die letzten Jahre entwickelt?
- Ist eine Änderung der Backup-Strategie sinnvoll und kann ggf. Platz eingespart werden? -
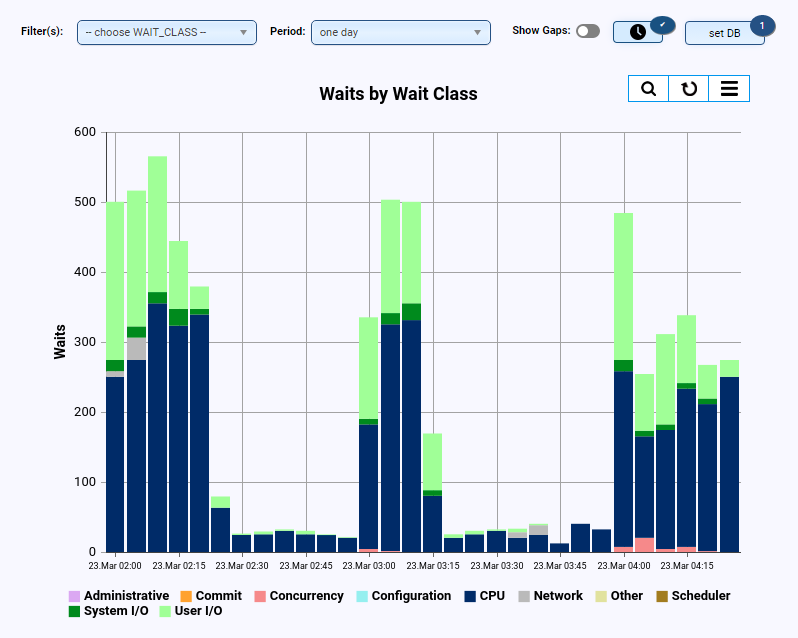
Wenn Sie keine Enterprise-Edition oder das Performance & Tuning-Pack nicht im Einsatz haben, ist die Performance-Auswertung weniger komfortabel, da der Einsatz von Cloud Control oder AWR-Reports nicht möglich ist. Durch das Einrichten entsprechender Regeln in DB-Harbour können viele Performance-Informationen abgefragt und visualisiert werden:
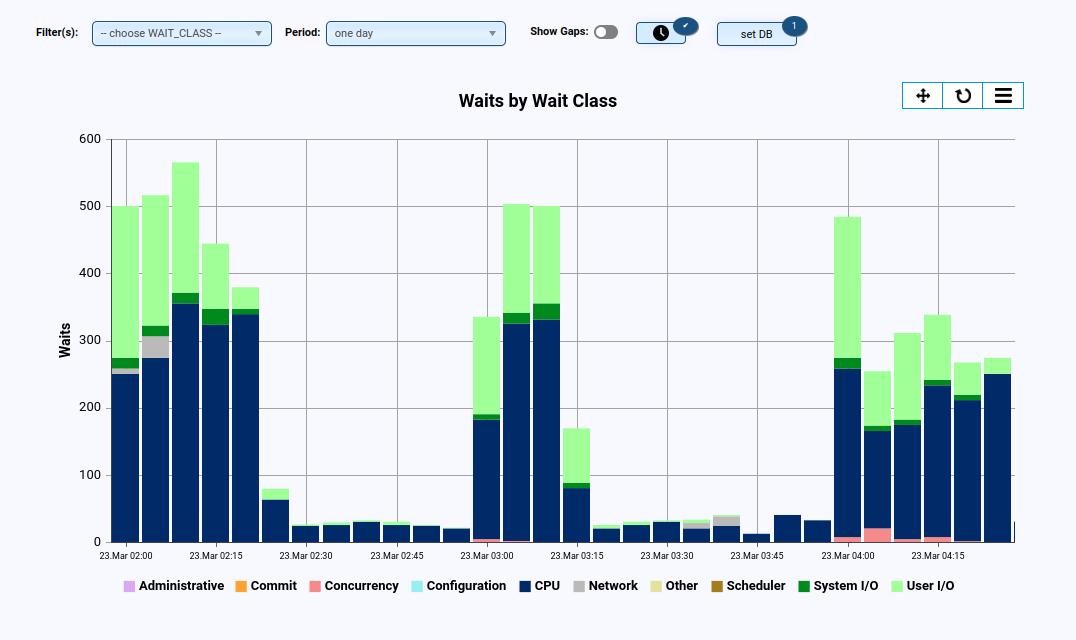
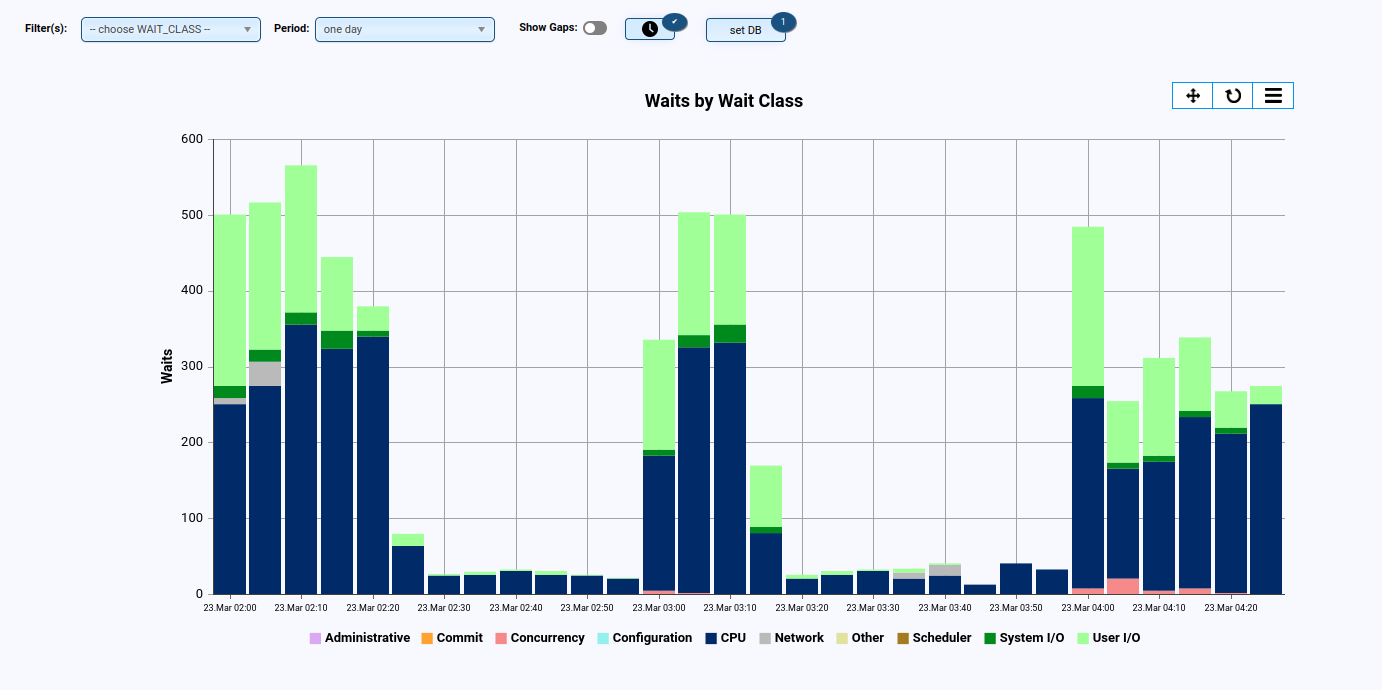
- Anzeige der Waits (z.B. pro Klasse und/oder Event)
- Top SQL-Statements (z.B. pro Anzahl der Ausführungen oder pro IO-/CPU-Last)
- Existieren längere Blocking-Sessions, Deadlocks oder sonstige "Langläufer"?
- Haben sich Ausführungspläne von Statements geändert?
- Wie haben sich die Anzahl der Prozesse und Sessions über die letzte Zeit verändert?
- Weitere Abfragen für Einzelfälle (z.B. Monitoring von Rollback-Operationen oder Refreshes von Materialized-Views)Wenn Sie keine Enterprise-Edition oder das Performance & Tuning-Pack nicht im Einsatz haben, ist die Performance-Auswertung weniger komfortabel, da der Einsatz von Cloud Control oder AWR-Reports nicht möglich ist. Durch das Einrichten entsprechender Regeln in DB-Harbour können viele Performance-Informationen abgefragt und visualisiert werden:
- Anzeige der Waits (z.B. pro Klasse und/oder Event)
- Top SQL-Statements (z.B. pro Anzahl der Ausführungen oder pro IO-/CPU-Last)
- Existieren längere Blocking-Sessions, Deadlocks oder sonstige "Langläufer"?
- Haben sich Ausführungspläne von Statements geändert?
- Wie haben sich die Anzahl der Prozesse und Sessions über die letzte Zeit verändert?
- Weitere Abfragen für Einzelfälle (z.B. Monitoring von Rollback-Operationen oder Refreshes von Materialized-Views) -
Bei großen Datenbank-Umgebungen ist, soweit möglich, eine Homogenisierung und Standardisierung sinnvoll. Diese erleichtert die Automatisierung von Aufgaben und bewirkt eine Reduzierung der Komplexität und Fehleranfälligkeit. Mittels DB-Harbour können viele Eigenschaften der Datenbank abgefragt und durch Vergleiche dauerhaft geprüft werden:
- Sind alle Redologgruppen einheitlich angelegt und gibt es Hinweise darauf, dass eine Anpassung sinnvoll ist?
- Welche Datenbank-Parameter sind gesetzt oder wurden verändert?
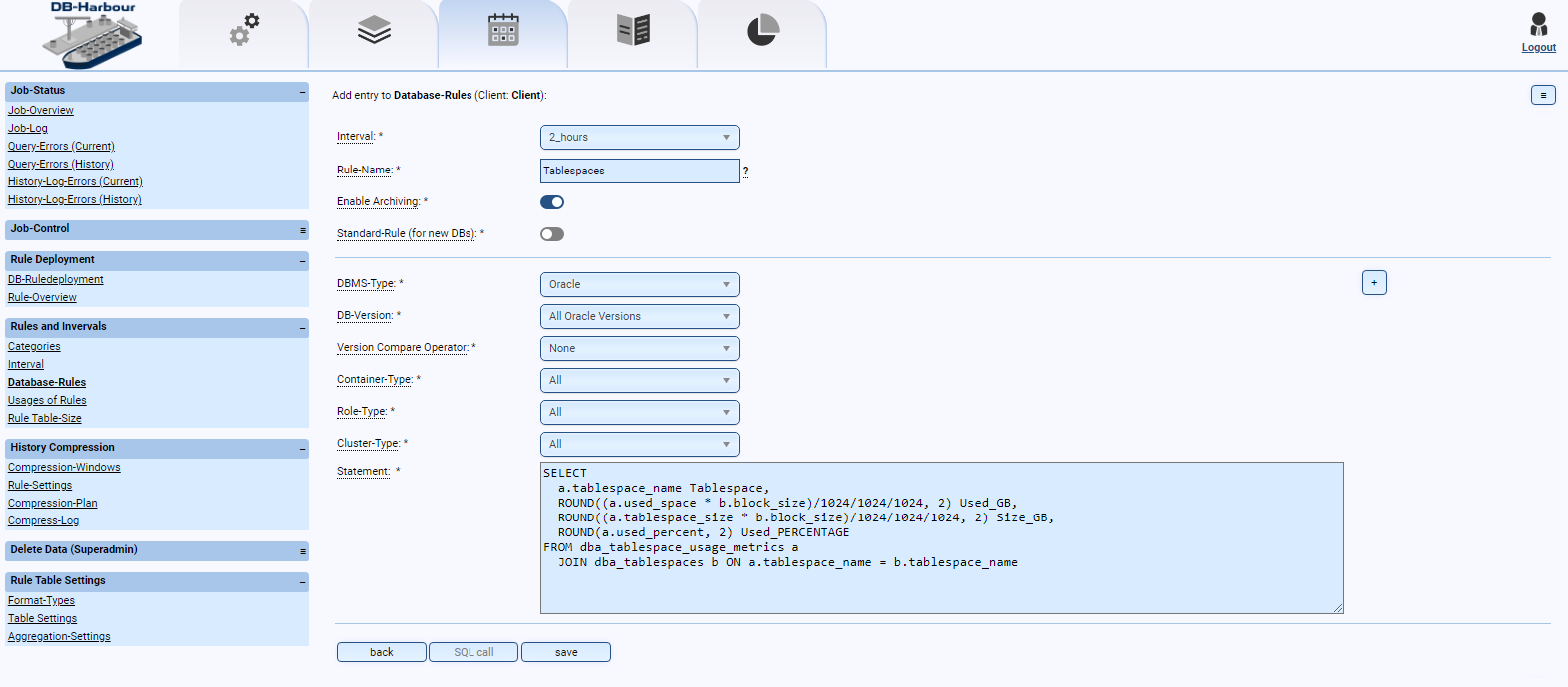
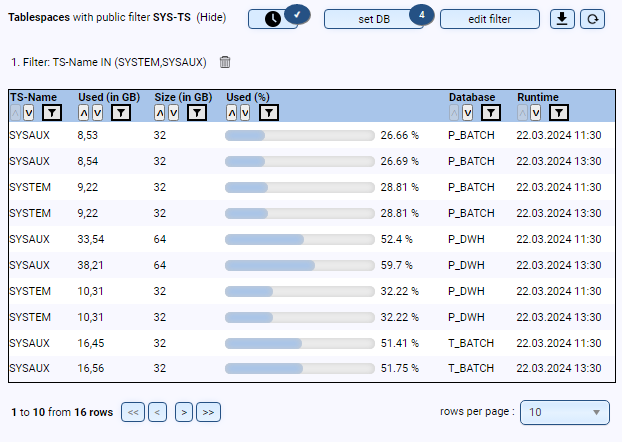
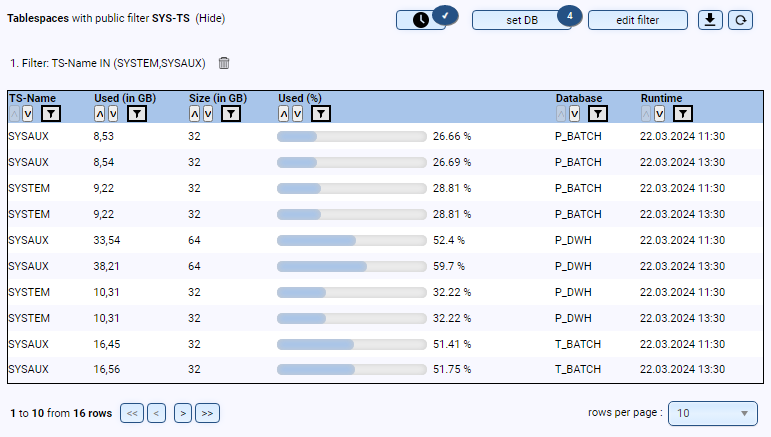
- Sind alle Tablespaces korrekt angelegt (z.B. Größe, Autoextend etc.)?
- Haben alle Datenbanken den gleichen Patch-Stand?
- Wie ist die Verteilung von PDBs zu CDBs und können hier Optimierungen vorgenommen werden?Bei großen Datenbank-Umgebungen ist, soweit möglich, eine Homogenisierung und Standardisierung sinnvoll. Diese erleichtert die Automatisierung von Aufgaben und bewirkt eine Reduzierung der Komplexität und Fehleranfälligkeit. Mittels DB-Harbour können viele Eigenschaften der Datenbank abgefragt und durch Vergleiche dauerhaft geprüft werden:
- Sind alle Redologgruppen einheitlich angelegt und gibt es Hinweise darauf, dass eine Anpassung sinnvoll ist?
- Welche Datenbank-Parameter sind gesetzt oder wurden verändert?
- Sind alle Tablespaces korrekt angelegt (z.B. Größe, Autoextend etc.)?
- Haben alle Datenbanken den gleichen Patch-Stand?
- Wie ist die Verteilung von PDBs zu CDBs und können hier Optimierungen vorgenommen werden? -
Neben den Metadaten über die Datenbank selbst (klassische Abfragen der V$- oder DBA_-Views) existieren i. d. R. auch applikationsspezifische Informationen, die mit DB-Harbour ausgewertet werden können. Hier einige Anwendungsfälle, die mittels eigener Regeln und entsprechender Select-Privilegien auf die Tabellen oder Views umsetzbar sind:
- Prüfung und Historisierung der Laufzeiten oder der Ergebnisse von Batch-Läufen (z.B. im DWH-Umfeld).
- Sammeln und Auswerten von applikationsspezifischen Logtabellen.
- Existieren Probleme in Applikations-Schemas der Datenbanken (z.B. invalide Objekte, gesperrte User oder "broken" Jobs)?
- Alle sonstigen via Select-Statement abfragbaren Informationen, die von Interesse sind.Neben den Metadaten über die Datenbank selbst (klassische Abfragen der V$- oder DBA_-Views) existieren i.d.R. auch applikationsspezifische Informationen die mit DB-Harbour ausgewertet werden können. Hier einige Anwendungsfälle die mittels eigener Regeln und entsprechender Select-Privilegien auf die Tabellen oder Views umsetzbar sind:
- Prüfung und Historisierung der Laufzeiten oder der Ergebnisse von Batch-Läufen (z.B. im DWH-Umfeld).
- Sammeln und Auswerten von applikationsspezifischen Logtabellen.
- Existieren Probleme in Applikations-Schemas der Datenbanken (z.B. invalide Objekte, gesperrte User oder "broken" Jobs)?
- Alle sonstigen via Select-Statement abfragbaren Informationen die von Interesse sind.