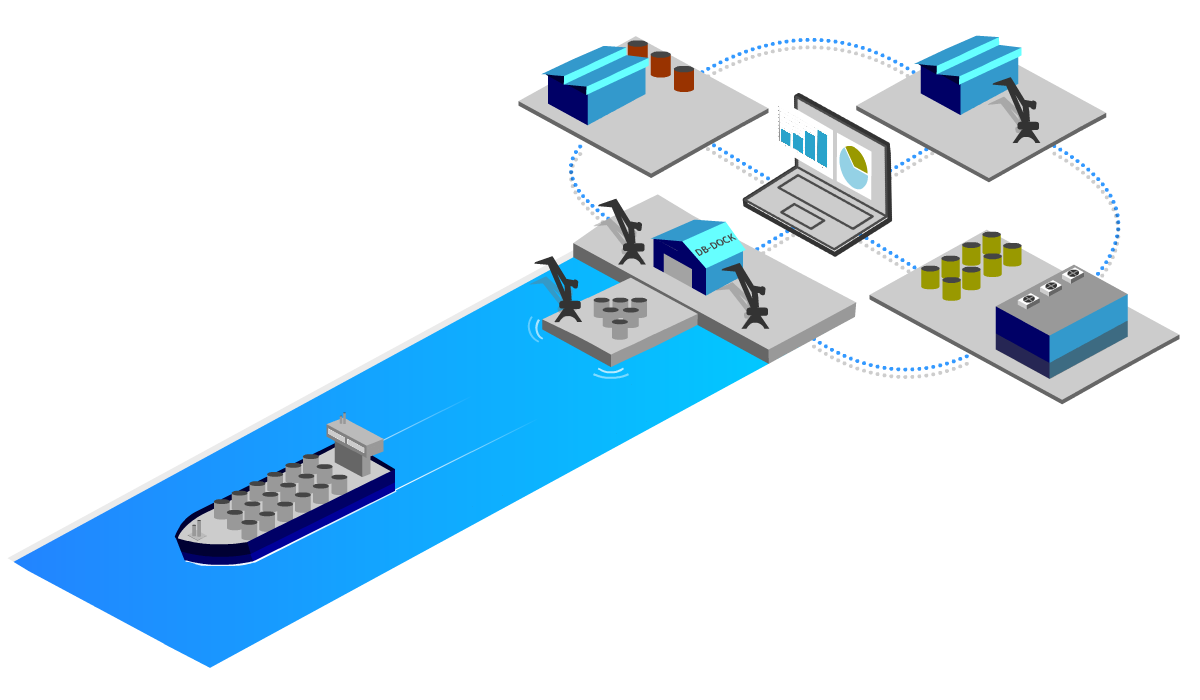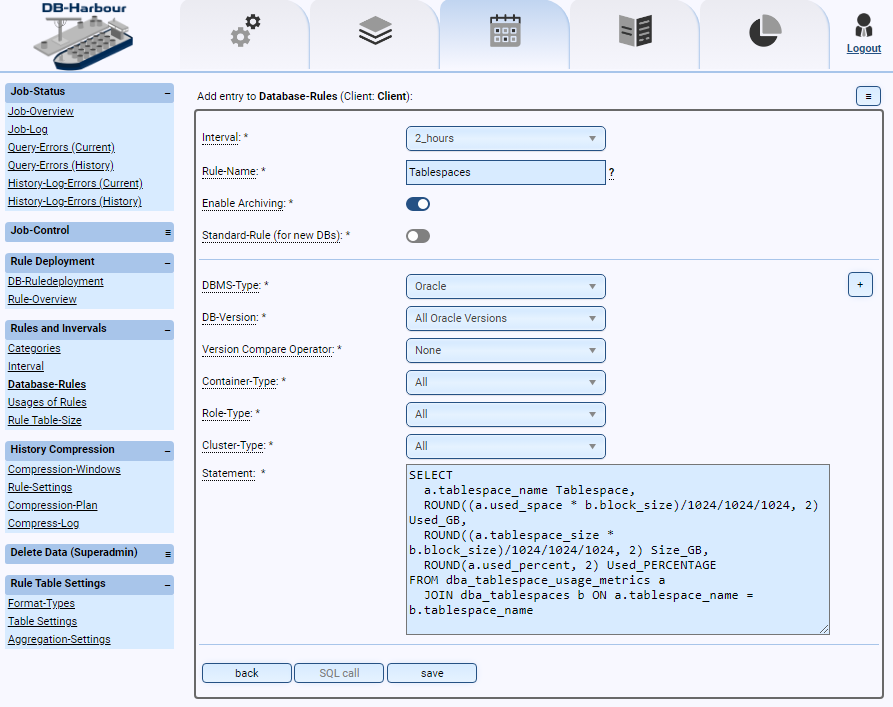
USE CASES
-
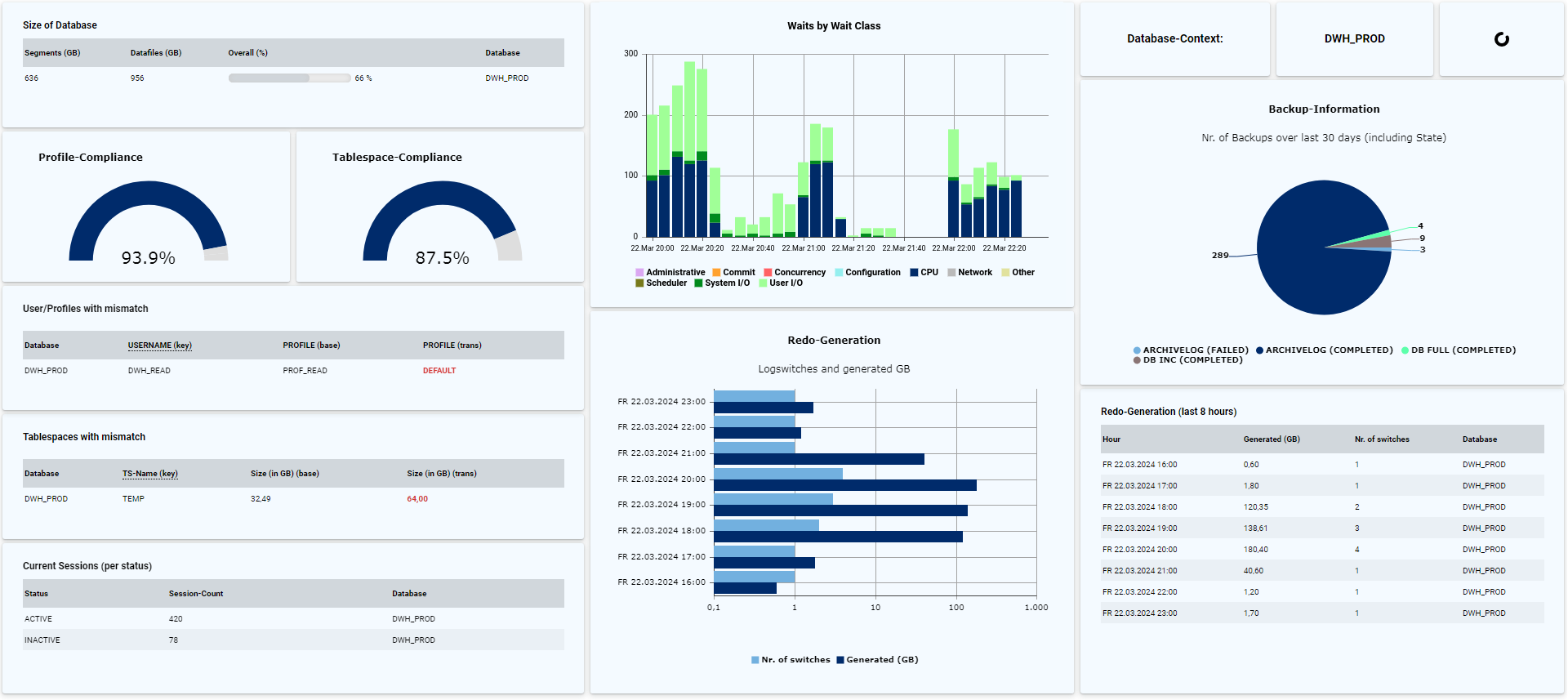
Whether for internal checks or external audits (e.g., CIS auditing) - with DB-Harbour you can check if your databases are configured in accordance with security requirements and automatically receive a permanent overview and historization:
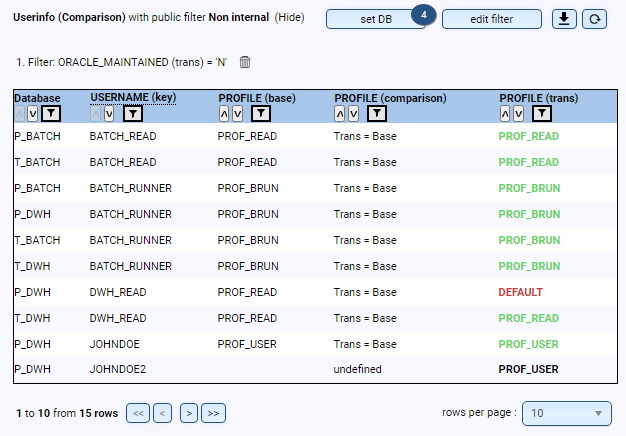
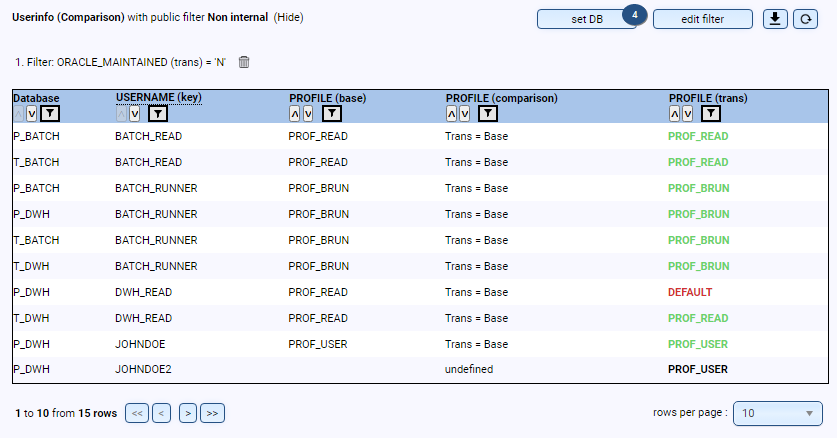
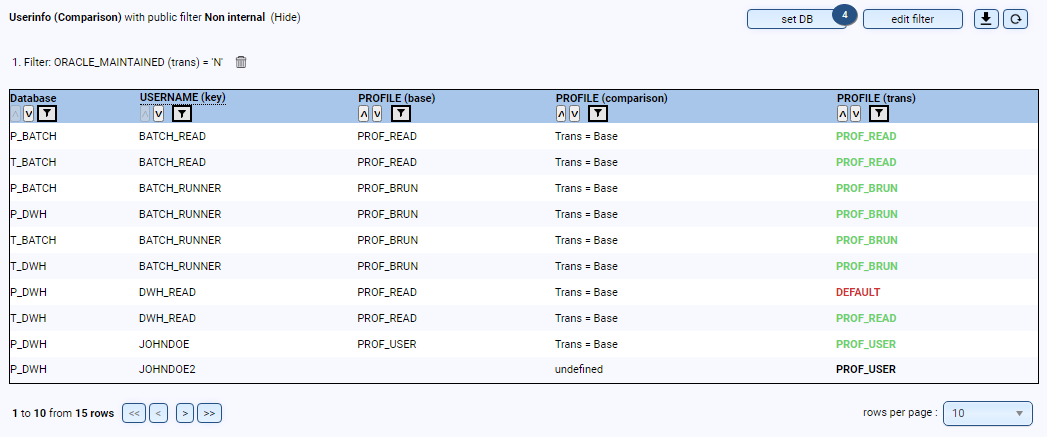
- Are the database users in the correct profiles, and what password versions do the users have?
- Are there users who have never logged in or who need to be deleted?
- Reading, central storage, and evaluation of the auditing views (e.g., fine-grained auditing or unified auditing)
- Preparing audits and permanently ensuring security requirements (e.g., checking for public database links or ANY grants)
- Further testing of your own security standards (e.g., configuration of database vault or TTS encryption)Whether for internal checks or external audits (e.g., CIS auditing) - with DB-Harbour you can check if your databases are configured in accordance with security requirements and automatically receive a permanent overview and historization:
- Are the database users in the correct profiles, and what password versions do the users have?
- Are there users who have never logged in or who need to be deleted?
- Reading, central storage and evaluation of the auditing views (e.g., fine-grained auditing or unified auditing)
- Preparing audits and permanently ensuring security requirements (e.g., checking for public database links or ANY grants)
- Further testing of your own security standards (e.g., configuration of database vault or TTS encryption) -
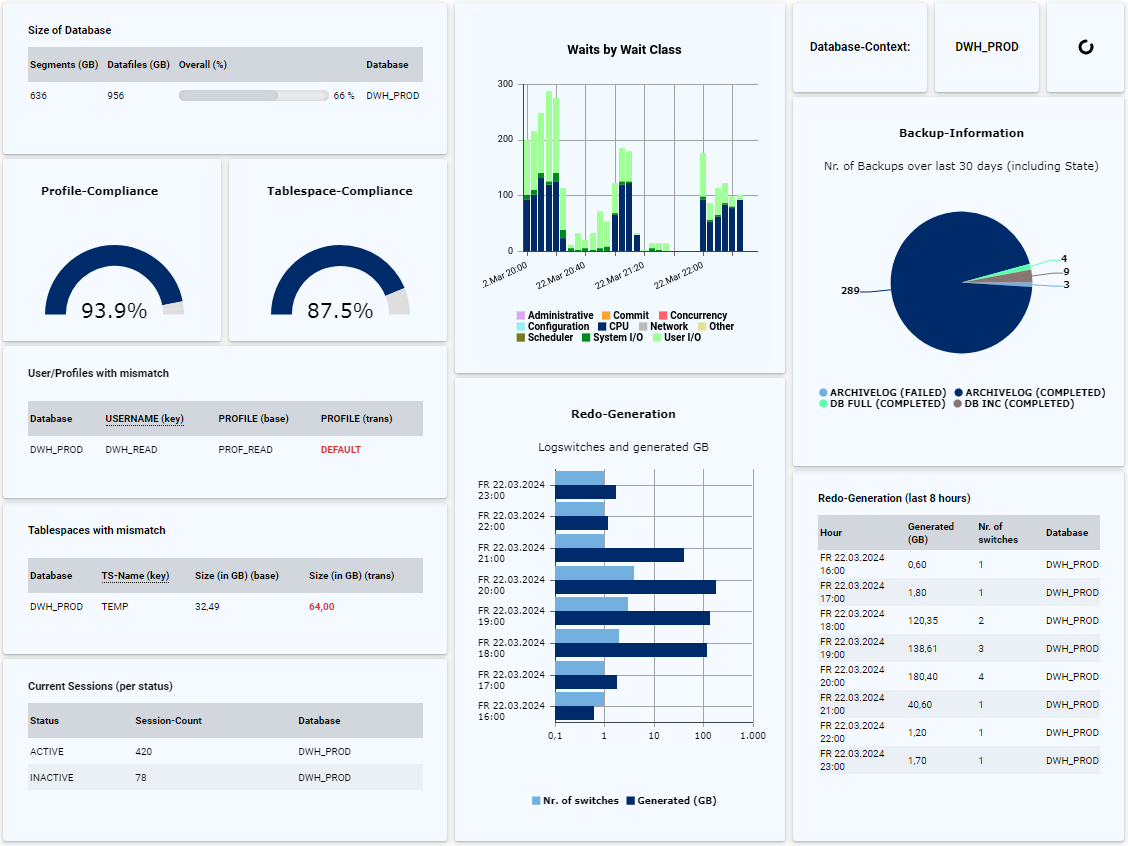
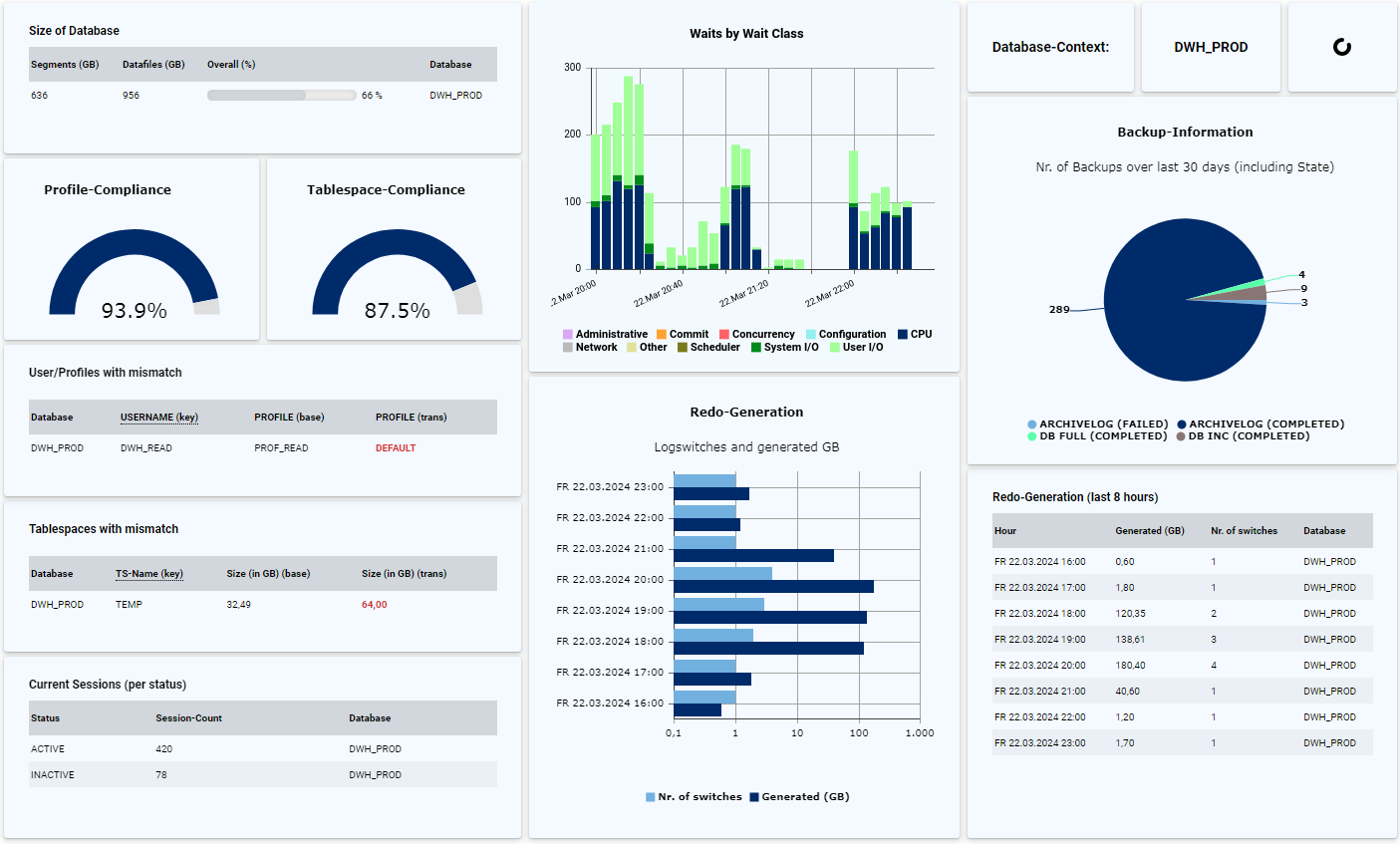
In contrast to monitoring tools, DB-Harbor can be used to carry out a more in-depth backup analysis, which can be used to avoid future problems in advance. With the help of DB-Harbour, many questions about the backup of Oracle databases can be answered quickly, conveniently, and permanently:
- Are there new datafiles or PDBs that have never been backed up?
- What is the status and timestamp of datafile copies?
- Free space within the Flash Recovery Area and in ASM disk groups
- Did any backups fail?
- How have the backup volume and backup durations developed over the last few years?
- Does changing the backup strategy make sense, and can space be saved?In contrast to monitoring tools, DB-Harbor can be used to carry out a more in-depth backup analysis, which can be used to avoid future problems in advance. With the help of DB-Harbour, many questions about the backup of Oracle databases can be answered quickly, conveniently, and permanently:
- Are there new datafiles or PDBs that have never been backed up?
- What is the status and timestamp of datafile copies?
- Free space within the Flash Recovery Area and in ASM disk groups
- Did any backups fail?
- How have the backup volume and backup durations developed over the last few years?
- Does changing the backup strategy make sense, and can space be saved? -
If you do not use an Enterprise Edition or the Performance & Tuning Pack, performance evaluation is less convenient because the use of Cloud Control or AWR reports is not possible. By setting up appropriate rules in DB-Harbour, a lot of performance information can be queried and visualized:
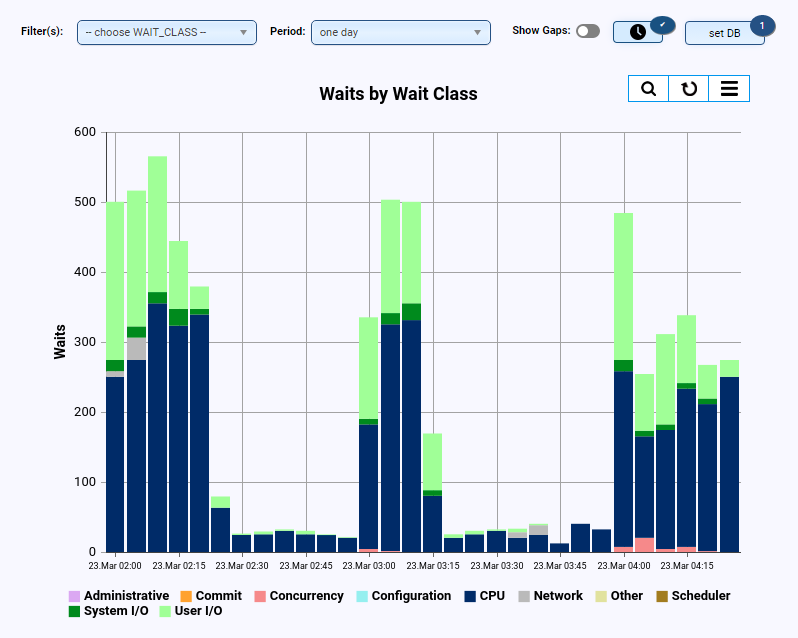
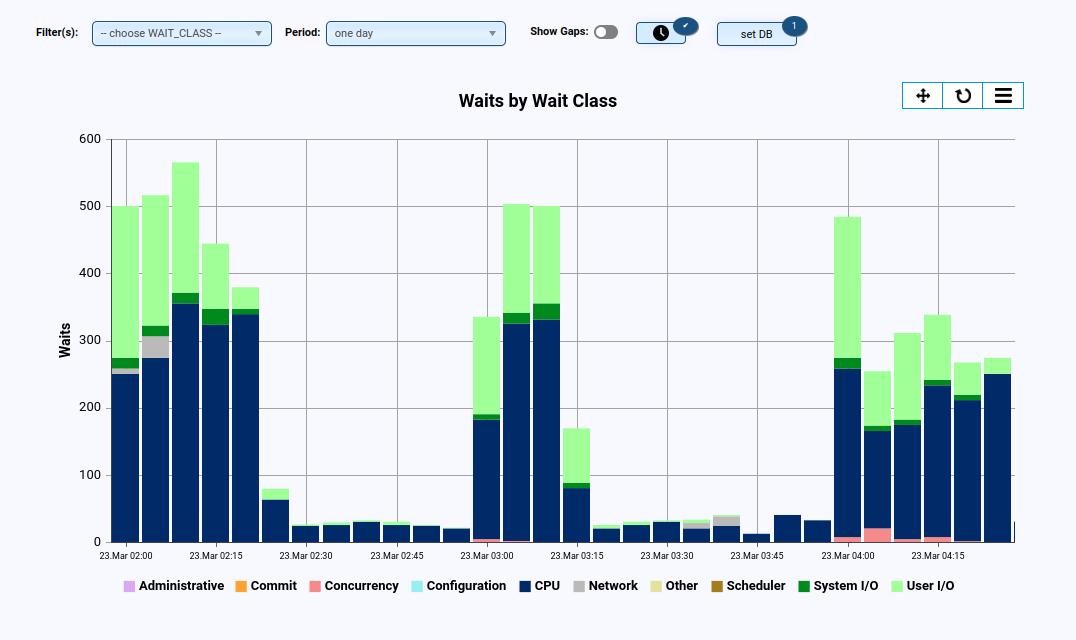
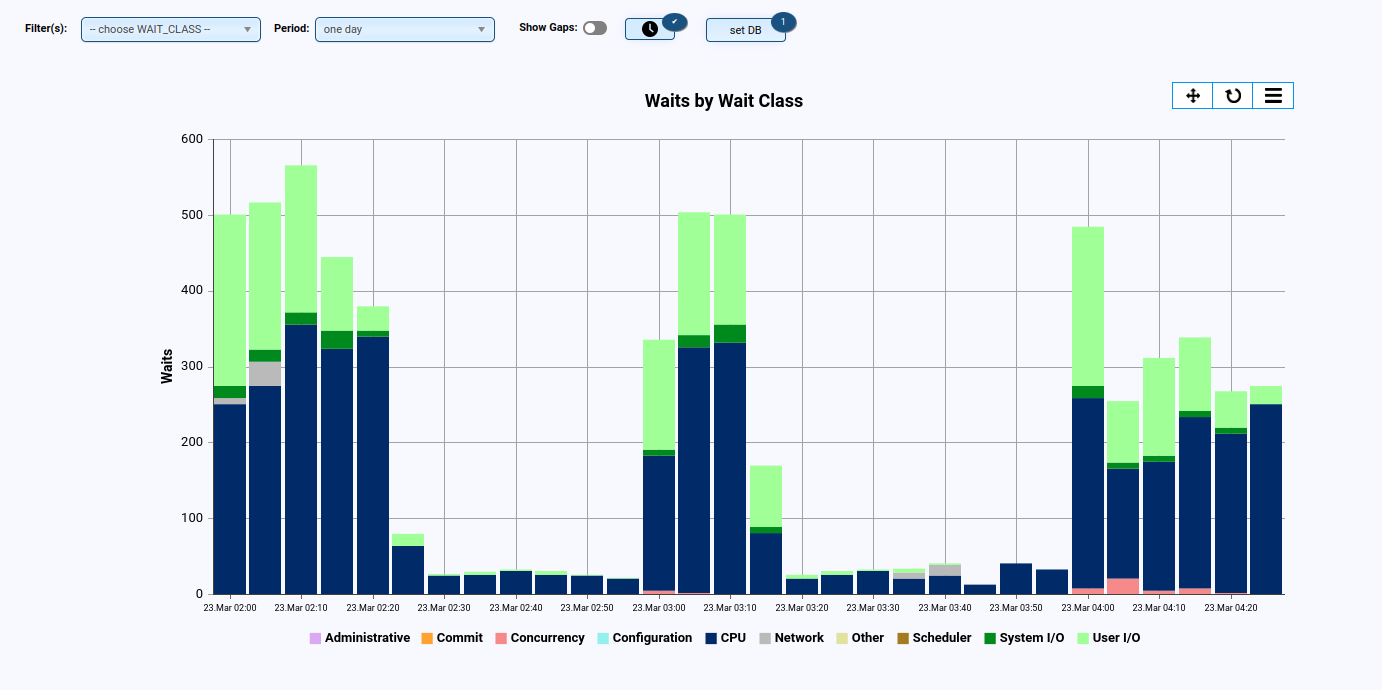
- Display of waits (e.g., per class and/or event)
- Top SQL statements (e.g., per number of executions or per IO/CPU load)
- Are there longer blocking sessions, deadlocks, or other “long runners”?
- Have execution plans of statements changed?
- How have the number of processes and sessions changed recently?
- Further queries for individual cases (e.g., monitoring of rollback operations or refreshes of materialized views)If you do not use an Enterprise Edition or the Performance & Tuning Pack, performance evaluation is less convenient because the use of Cloud Control or AWR reports is not possible. By setting up appropriate rules in DB-Harbour, a lot of performance information can be queried and visualized:
- Display of waits (e.g., per class and/or event)
- Top SQL statements (e.g., per number of executions or per IO/CPU load)
- Are there longer blocking sessions, deadlocks, or other “long runners”?
- Have execution plans of statements changed?
- How have the number of processes and sessions changed recently?
- Further queries for individual cases (e.g., monitoring of rollback operations or refreshes of materialized views) -
For large database environments, homogenization and standardization make sense wherever possible. This makes it easier to automate tasks and reduces complexity and susceptibility to errors. Using DB-Harbour, many properties of the database can be queried and permanently checked through comparisons:
- Are all Redolog groups created uniformly, and is there any indication that an adjustment makes sense?
- Which database parameters are set or have been changed?
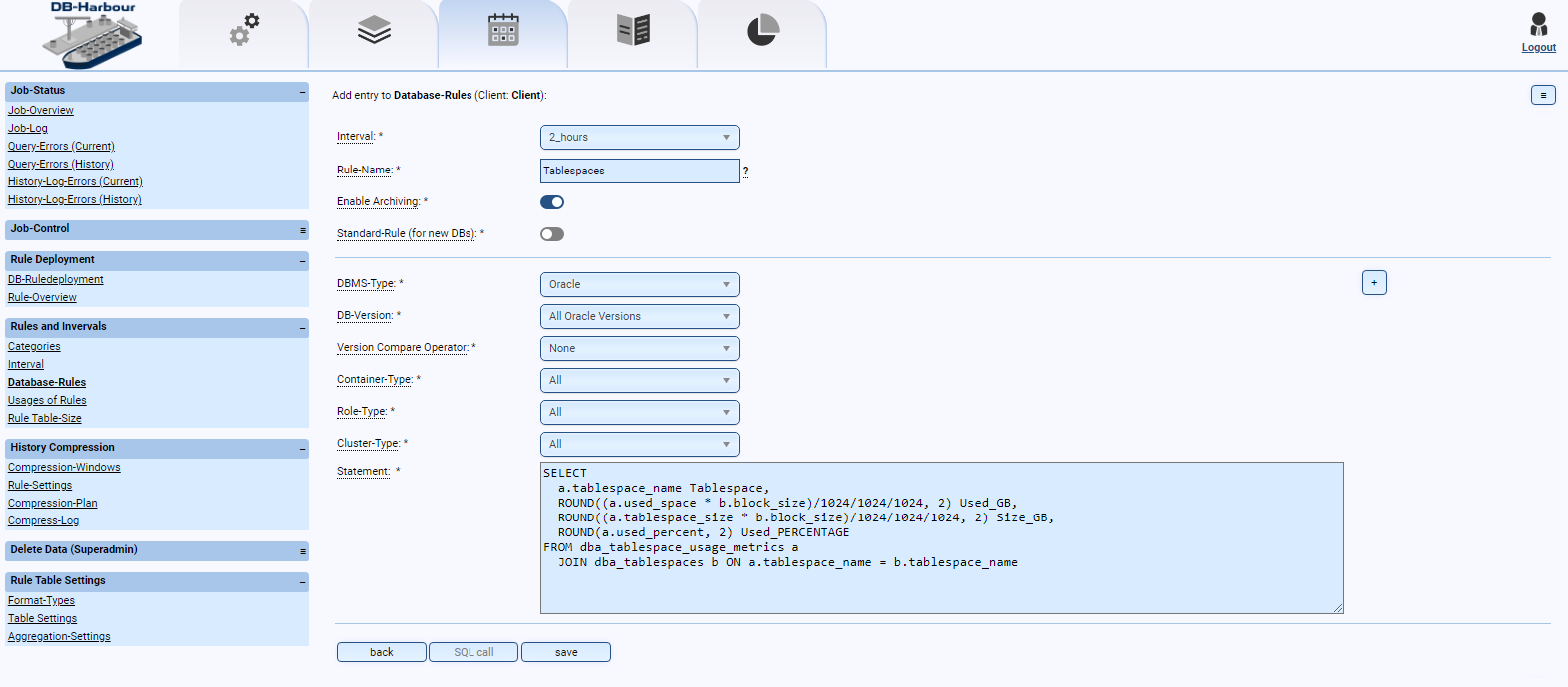
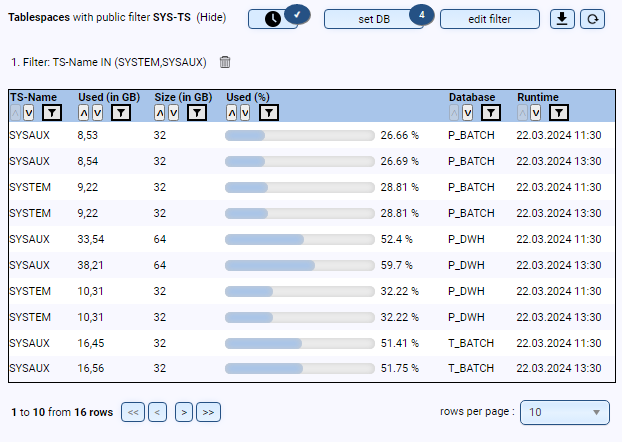
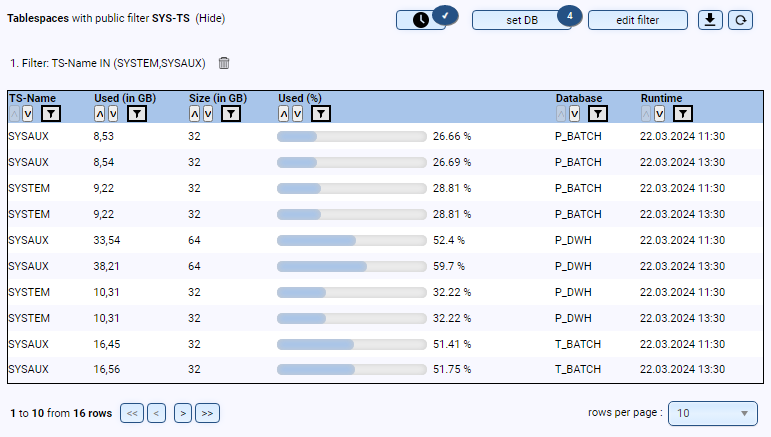
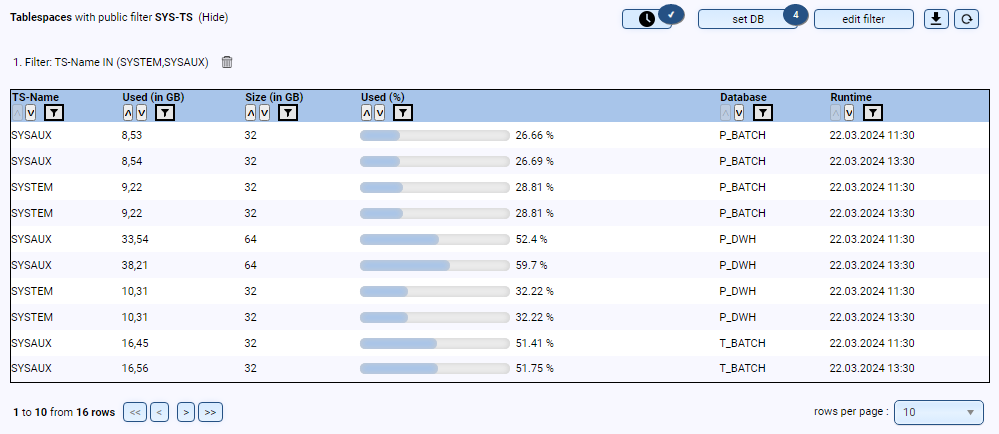
- Are all tablespaces created correctly (e.g., size, autoextend, etc.)?
- Do all databases have the same patch level?
- How is the distribution of PDBs to CDBs, and can optimizations be made here?For large database environments, homogenization and standardization make sense wherever possible. This makes it easier to automate tasks and reduces complexity and susceptibility to errors. Using DB-Harbour, many properties of the database can be queried and permanently checked through comparisons:
- Are all Redolog groups created uniformly, and is there any indication that an adjustment makes sense?
- Which database parameters are set or have been changed?
- Are all tablespaces created correctly (e.g., size, autoextend, etc.)?
- Do all databases have the same patch level?
- How is the distribution of PDBs to CDBs, and can optimizations be made here? -
In addition to database metadata (classic queries from the V$- or DBA_-views), there is usually also application-specific information that can be evaluated with DB-Harbour. Here are some use cases that can be implemented on the tables or views using your own rules and corresponding select privileges:
- Checking and historizing runtimes or results of batch runs (e.g., in your DWH environment).
- Collecting and evaluating application-specific log tables.
- Are there problems in application schemas of the databases (e.g., invalid objects, blocked users, or "broken" jobs)?
- All other information that is of interest and can be queried via a select statement.In addition to database metadata (classic queries from the V$- or DBA_-views), there is usually also application-specific information that can be evaluated with DB-Harbour. Here are some use cases that can be implemented on the tables or views using your own rules and corresponding select privileges:
- Checking and historizing runtimes or results of batch runs (e.g., in your DWH environment).
- Collecting and evaluating application-specific log tables.
- Are there problems in application schemas of the databases (e.g., invalid objects, blocked users, or "broken" jobs)?
- All other information that is of interest and can be queried via a select statement.